I had been playing around with using Google’s Gemino 2.5 Pro LLM to make Python scripts for working with GPS files: for instance, adding data on the speed I was traveling at every point along recorded tracks.
The process is a bit awkward. The LLM doesn’t know exactly what system you are implementing the code in, which can lead to a lot of back and forth when commands and the code content aren’t completely right.
The other day, however, I noticed the ‘Build’ tab on the left side menu of Google’s AI Studio web interface. It provides a pretty amazing way to make an app from nothing, without writing any code. As a basic starting point, I asked for an app that can go through a GPX file with hundreds of hikes or bike rides, pull out the titles of all the tracks, and list them along with the dates they were recorded. This could all be done with command-line tools or self-written Python, but it was pretty amazing to watch for a couple of minutes while the LLM coded up a complete web app which produced the output that I wanted.
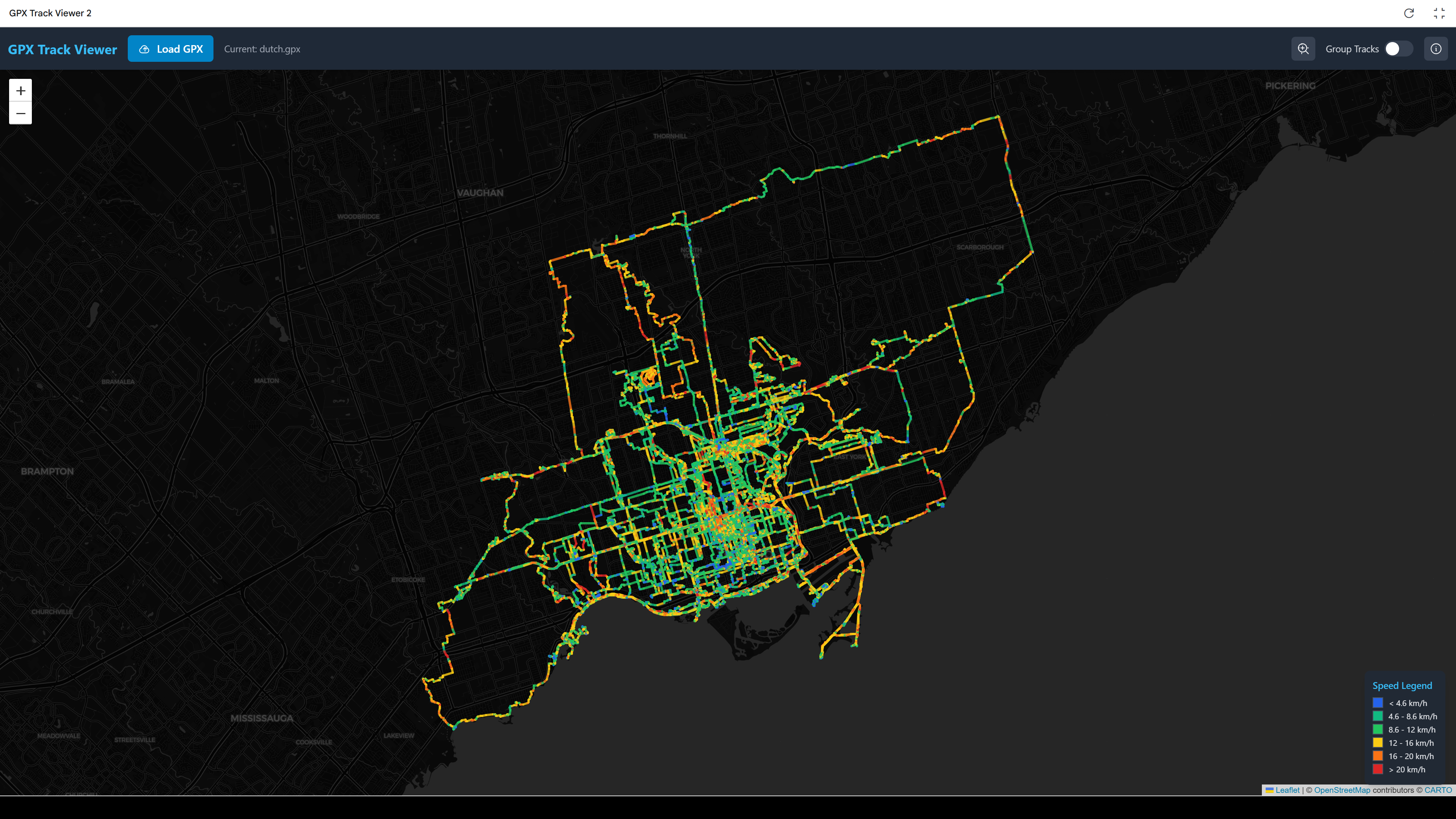
Much of this has been in service of a longstanding goal of adding new kinds of detail to my hike and biking maps, such as slowing the slope or speed at each point using different colours. I stepped up my experiment and asked directly for a web app that would ingest a large GPX and output a map colour coded by speed.
Here are the results for my Dutch bike rides:
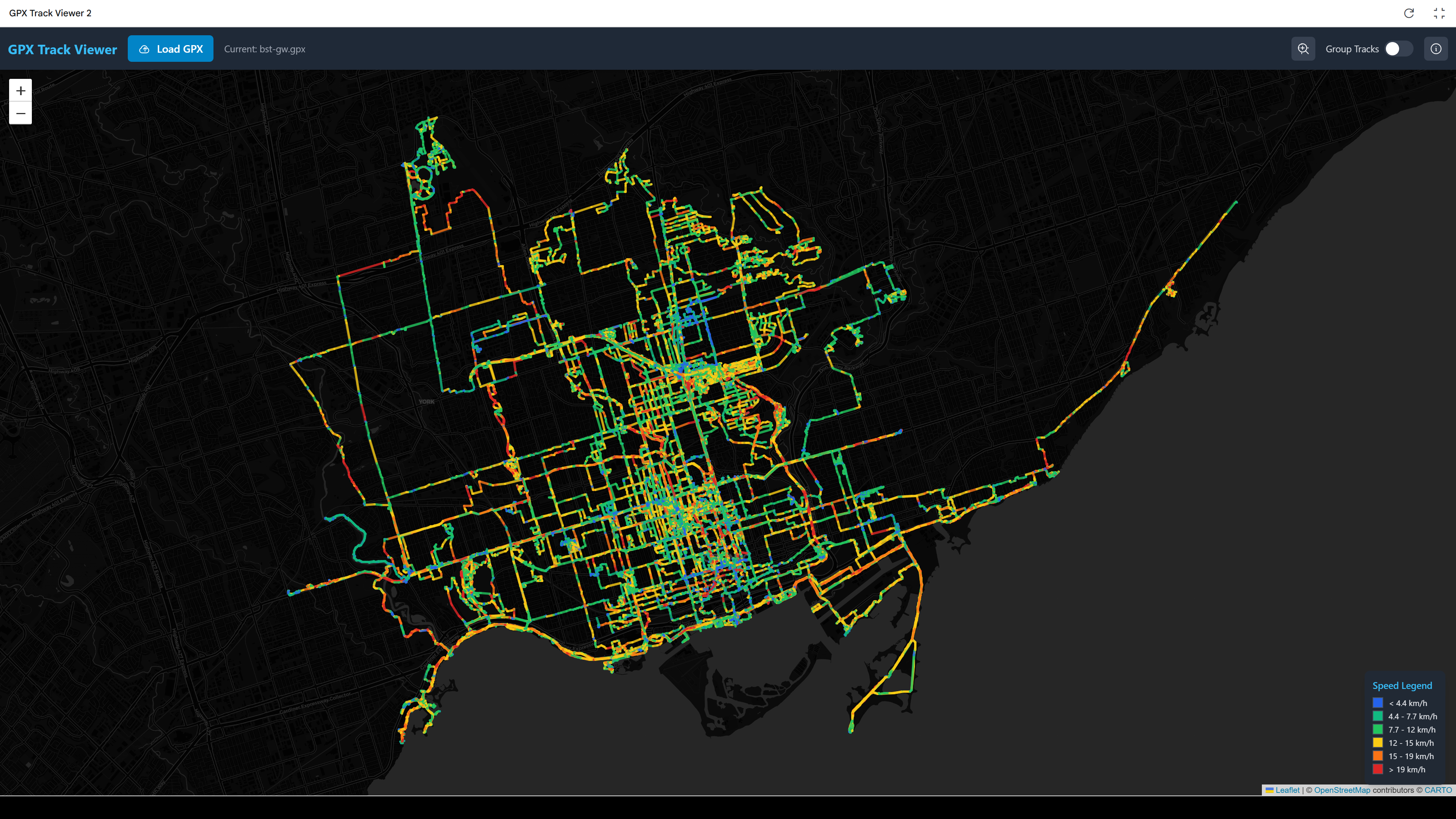
And the mechanical Bike Share Toronto bikes:
I would prefer something that looks more like the output from QGIS, but it’s pretty amazing that it’s possible. It also had a remarkable amount of difficulty with the seemingly simple task of adding a button to zoom the extent of the map to show all the tracks, without too much blank space outside.
Perhaps the most surprising part was when at one point I submitted a prompt that the map interface was jittery and awkward. Without any further instructions it made a bunch of automatic code tweaks and suddenly the map worked much better.
It is really far, far from perfect or reliable. It is still very much in the dog-playing-a-violin stage, where it is impressive that it can be done at all, even if not skillfully.